This introduction is intended for those who already have some familiarity with python. You should know what variables, functions, operators are and how loops and if statement work. The most important thing you can do is practice. This tutorial won't give you much practice. But it will help to show how Python fits together, some general principles, and how we will be using it during the MSc in Data Science. We will make reference to the W3 Schools' Python tutorial which gives the basics.
Please install Anaconda and check that the Spyder editor works, in advance. Anaconda is a suite of Python tools that includes Python itself. See below for more details.
Introducing Python¶
Python is an interpreted, high-level, general-purpose programming language that works on many platforms. Its popularity for Data Science is largely down to its simplicity and the huge number of libraries that are available for it. There are a only few basics to learn, but note that most of your work will be using libraries and most of your Python effort will be about learning how to use individual libraries.
It is relately easy to write Python by hacking together code from examples on the web, but I recommend that you try and understand the syntax and how this code works. This will make things easier in the long term.
Python has been around since the early 1990s, but 2008 saw the release of Python 3, a major revision that is not completely compatible with previous releases.
Before you start this, please install Anaconda on your computer (see below).
Anaconda¶
Python is free. We will be using the Anaconda distribution, which includes a suite of tools including those that help you install/update libraries. Install it here and see the quick instructions in their cheatsheet.
"Spyder" as a Python editor¶
Python code is simply plain text file. You can write it in any editor that saves plain-text (e.g. Notepad) and then running this file through a python interpreter to execute it (python myPythonCode.py).
However, using specific python editor makes life a bit easier for us. We will be using the "Spyder" editor in this tutorial, because it contains a lot of built-in tools for helping you write python. It is part of Anaconda, so you will have it on your computer. Other editors will be covered later. You can launch it from the Anaconda Navigator.
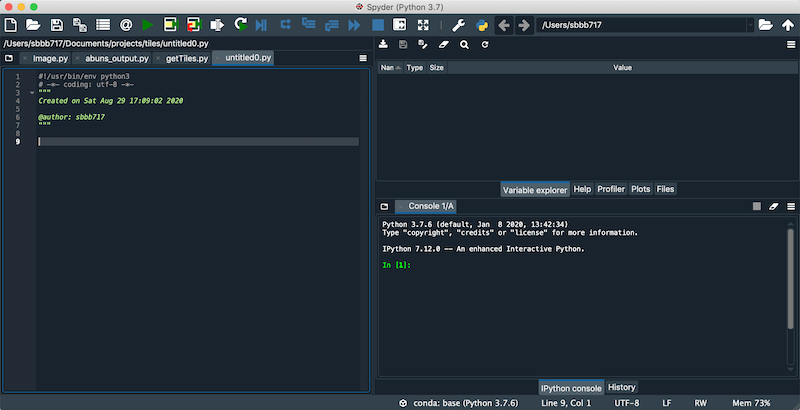
I want to draw your attention to three panels of the Spyder interface:
- Code (left): this is where your python files can be edited
- IPython console (bottom right): to run python commands immediately
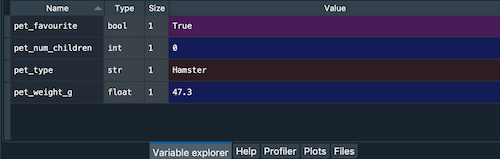
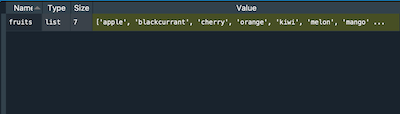
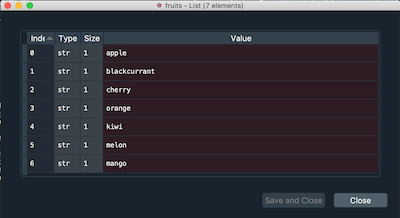
- Variable explorer (top right): to see what variables you have
Write your first line of python in the traditional way by pasting the following into the IPython console: