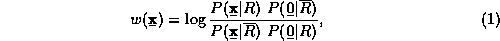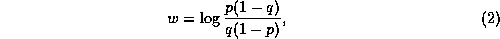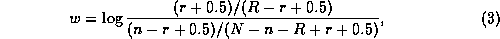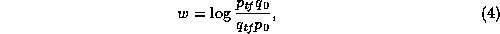The basic weighting function used is that developed in [6], and may be expressed as follows:
where x is a vector of information about the document,
0 is a reference vector representing a zero-weighted document, and
R and 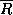 are relevance and non-relevance respectively.
are relevance and non-relevance respectively.
For example, each component of x may represent the presence/absence of a query term in the document or its document frequency; 0 would then be the ``natural'' zero vector representing all query terms absent.
In this formulation, independence assumptions (or, indeed, Cooper's assumption of ``linked dependence'' [7]), lead to the decomposition of w into additive components such as individual term weights. In the presence/absence case, the resulting weighting function is the Robertson/Sparck Jones formula [8] for a term-presence-only weight, as follows:
where 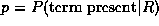 and
and
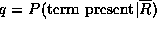 .
.
With a suitable estimation method, this becomes:
where N is the number of indexed documents, n the number containing
the term, R the number of known relevant documents, and
r the number of these containing the term.
This approximates to inverse collection frequency (ICF) when
there is no relevance information. It will be referred to below
(with or without relevance information) as 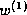 .
.
If we deal with within-document term frequencies rather than merely presence and absence of terms, then the formula corresponding to 2 would be as follows:
where 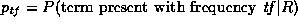 ,
,
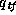 is the corresponding probability for
is the corresponding probability for 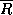 , and
, and
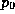 and
and 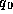 are those for term absence.
are those for term absence.