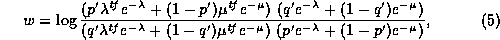The 2--Poisson model is a specific distributional assumption based on the eliteness hypothesis discussed above. The assumption is that the distribution of within-document frequencies is Poisson for the elite documents, and also (but with a different mean) for the non-elite documents.
It would be possible to derive this model from a more basic one, under which a document was a random stream of term occurrences, each one having a fixed, small probability of being the term in question, this probability being constant over all elite documents, and also constant (but smaller) over all non-elite documents. Such a model would require that all documents were the same length. Thus the 2--Poisson model is usually said to assume that document length is constant: although technically it does not require that assumption, it makes little sense without it. Document length is discussed further below (section 5).
The approach taken in [6] was to estimate the parameters of the two Poisson distributions for each term directly from the distribution of within-document frequencies. These parameters were then used in various weighting functions. However, little performance benefit was gained. This was seen essentially as a result of estimation problems: partly that the estimation method for the Poisson parameters was probably not very good, and partly because the model is complex in the sense of requiring a large number of different parameters to be estimated. Subsequent work on mixed-Poisson models has suggested that alternative estimation methods may be preferable [9].
Combining the 2--Poisson model with formula 4, under the various assumptions given about dependencies, we obtain [6] the following weight for a term t:
where 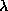 and
and 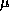 are the Poisson means for
are the Poisson means for 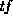 in the
elite and non-elite sets for t respectively,
in the
elite and non-elite sets for t respectively,
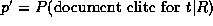 , and
, and
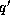 is the corresponding probability for
is the corresponding probability for 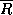 .
.
The estimation problem is very apparent from equation 5, in that there are four parameters for each term, for none of which are we likely to have direct evidence (because of eliteness being a hidden variable). It is precisely this estimation problem which makes the weighting function intractable. This consideration leads directly to the approach taken in the next section.